Algorithm personalizes which cancer mutations are best targets for immunotherapy

As tumor cells multiply, they often spawn tens of thousands of genetic mutations. Figuring out which ones are the most promising to target with immunotherapy is like finding a few needles in a haystack. Now a new model developed by researchers in the Abramson Cancer Center at the University of Pennsylvania hand-picks those needles so they can be leveraged in more effective, customized cancer vaccines. Cell Systems published the data on the model's development today, and the algorithm is already available online as an open source technology to serve as a resource.
"There are mutations in tumors that can lead to powerful immune responses, but for every one mutation that generates a robust response, about 50 mutations don't work at all, which means the signal-to-noise ratio is not great," said the study's lead author Lee P. Richman, an MD/Ph.D. candidate in Cancer Biology in the Perelman School of Medicine at the University of Pennsylvania. "Our model works like a filter that highlights the signal and shows us which targets to focus on."
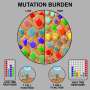
Currently, sequencing a tumor and identifying possible immunotherapies is based on a measurement called tumor mutations burden (TMB), essentially a measure of the rate of mutations present in a given tumor. Tumors with a high rate of mutation are more likely to respond to immunotherapy targeting inhibitors like PD-1. The problem is that as cancer cells divide, they mutate at random, and since they divide exponentially, the potential mutations are almost infinite. This means that while a given immunotherapy can target some percentage of cancer cells, it may not be enough to be an effective treatment for any given patient.
The Penn team's model looks instead at protein sequences from samples of individual patients and evaluates how much of it looks similar to healthy cells and how much looks different enough that the immune system might react to it. The more it is dissimilar, the better immunotherapy target it makes because it's more likely to attract and activate therapies with less collateral damage to healthy cells. The model's prediction is also personalized to each patient's sample. The team analyzed samples of 318 patients from five different clinical trial data sets and not only confirmed the association between dissimilarity and promise as an immunotherapy target, but also found that dissimilarity correlated to increased overall survival after PD-1 therapy in patients with non-small cell lung cancer.
"With so many different possibilities of mutations, we essentially boiled the question of which targets to use down to a math problem, then developed an algorithm to solve it," said Andrew J. Rech, MD, Ph.D., a resident in Pathology and Laboratory Medicine and the study's co-senior author along with Robert H. Vonderheide, MD, DPhil, director of the Abramson Cancer Center. "We also knew it was important to make this model available for other researchers to help inform vaccine development and clinical trials."
The researchers say in addition to its use in trials, future work will also include applying the tool to more data sets to refine the algorithm.